


Mario & Luigi vs. GPT-4
Why countries should allow for the free proliferation of GPT-4 within their borders

Welcome back to The Innovation Armory! Today’s piece is on Italy’s decision to ban OpenAI’s GPT-4. I argue against this decision using a five part framework including:
Negative opportunity costs for Italy’s geopolitical standing from an innovation and economic perspective
The constraints on enforcement that will be posed by continued diversification and abstraction of the average software supply chain
Low probability of harm given the nature of data privacy violations relative to Italy’s standing in the digital economy
A mismatch in timing between when the potential rights harm that occurred and the ability to derive benefit from the model in the status quo
The distinction between public and private value capture from data and how nations ought to crack down harder on the latter
While I was writing this piece Italy actually decided to lift its ban. What timing! If you liked this piece feel free to subscribe for future updates below:

Italy recently became one of the first countries internationally to ban OpenAI’s GPT-4 large language model. Considering how explosively GPT-4 and generative AI models came onto the scene this year, this is a large development for the average Italian citizen who will now be locked out of a core piece of AI innovation. The reaction in has been highly polarized:
Italy’s deputy prime minister criticized data authorities for banning the service on the basis that its data privacy violations are no less significant than other online services
Select countries have criticized the ban, while others like Germany have considered instituting their own ban
The Italian ban is based on a decision that OpenAI does not have the right to harvest user data without proper informed consent processes in place. Specifically, in order to be able to operate in the nation eventually, Italy announced that OpenAI will need to:
Clarify the legal basis that it is using to collect user data either for reasons of Consent or Legitimate Interests
Give users the ability to object to processing of their data for model training purposes
Conduct a local campaign to inform Italians that their data is being processed
These hurdles are not particularly difficult to meet. The Legitimate Interests basis for legal processing requires the meeting of three tests: 1) There is a legitimate purpose for processing data, 2) Processing is necessary for that purpose and 3) The purpose outweighs any violation of individual liberties in the process. “Legitimacy” is a subjective standard and there is not a clear brightline for what purpose counts as legitimate. GPT-4 development has many purposes including the advancement of humanity, acceleration of the digital economy and automation of tasks for humanity. The harvesting of data to train the AI is definitionally necessary to that purpose given how the technology works. Any one individual whose rights may be violated when the AI is queried suffers very little tangible / direct harm relative to the goals that AI research advances. Under GDPR, interpretations tend to focus on direct / tangible harms when evaluating the third test. It will be interesting to see how OpenAI gives users the ability to opt out of data processing given it has already been trained on massive datasets that likely include the data of Italian nationals. I suspect this will likely take the form of opting out of data harvesting from specific new queries that Italian nationals make to GPT-4. There’s nothing in Italy akin to the great firewall of China that prevents OpenAI from scraping publicly accessible data about Italian nationals. While I do believe that education about the nature of data collection is important, I think it is important for AI education to not overemphasize the risks of data harvesting relative to the benefits of applications built on top of large language models. I hope OpenAI is able to also emphasize the strengths of GPT-4 in these local campaigns without focusing too much on the negatives.
The harm to Italy’s population from banning OpenAI relative to the risk of data collection is quite high. I offer a five part framework for analyzing Italy’s decision:

Geopolitical Innovation – Large language models have incredibly powerful potential use cases that run the gamut from real estate to law to service work to medicine. Estimates by the American Enterprise Institute indicate that deployment of AI could increase national GDP by approximately 7% per annum. By automating tasks normally done by humans, it has the potential to substantially increase labor productivity and allow more of humanity to shift their time and attention to new areas of the economy that generate more value, or co-pilot work with AIs to generate economic value in existing areas of the economy. Bill Gates recently wrote a piece comparing GPT-4 to the invention of personal computers and of the internet. By banning GPT-4, Italy is effectively preventing its citizens from participating in innovation benefits that rival if not surpass productivity and economic gains achieved by the advent of the internet itself:

I believe the Italian authorities are severely constraining the potential levels of innovation of the next generation in Italy by cutting off access to such a powerful tool. This has geopolitical implications for how quickly Italy will grow its economy, how fast it will be able to develop cybersecurity protections and innovations and more broadly how happy its population will be as citizens’ livelihoods are made more difficult without access to public tools that will help automate and offload manual tasks. I fear countries that adopt the approach of Italy will wither into small fish in the ocean of geopolitics. There will be anti-amalgamation effects that occur on the backs of this decision as well since the top engineering talent will flock out of Italy for other countries, leading to brain drain and capital flight of some deep pockets in the technology industry:

There is something to be said about preserving Italian data to be used for an Italian national champion in the AI space and not allowing businesses in other countries to be the beneficiaries instead. While this has potential positive geopolitical implications in the short-run, in the long run, a closed model that is only trained on the population of one national group will lose out to open source, broader platforms like OpenAI by sheer virtue of data access and volume. Further, there are so many technologies that countries choose not to regulate until much later into their lifecycles (see my piece on the Dark Side of Innovation for more context here). The Italian government is choosing ban a technology where the geopolitical and societal cost of not participating is likely even higher from day 1 relative to other technologies.
Enforcement Potential – large language models increasingly will be utilized as a small part of a broader software supply chain. Chat GPT-4 and Dalle currently work by requiring users to input manual prompts about what output they’d like generated. However, it is possible to instruct large language models like GPT-4 to generate their own queries to perform iterative self-sustaining tasks through goal-oriented work. These goal-oriented models can be built on top of large language models to enable tasks to be automatically performed on a given goal parameter without human intervention. As more goal-oriented programs are built on top of OpenAI and further applications are abstracted out of these goal oriented use cases, how will Italian authorities be able to tell which applications are using GPT-4? Further, what amount of use of GPT-4 in the totality of the software supply chain will be substantial or robust enough to necessitate the banning of that particular private application?

As open source software supply chains become more complex, it will increasingly become difficult or near impossible to enforce these bans especially if the servers running queries and goal directed models on GPT-4 are based offshore.
Probability of Harm - GPT-4 is trained on over 100 trillion parameters. What percentage of those parameters likely come from Italy as opposed to other countries? Well there are a variety of factors to look at to make this estimate including: i) population size, ii) relative Italian internet usage, iii) internet users in Italy, iv) applications originating in Italy and v) digital economic activity in Italy to name a few points that could be helpful. Italy isn’t exactly a technology hub in Europe compared to other cities so I’d venture that its internet user base is at best proportionate to its population. The watermark on Italy’s data inclusion in the GPT-4 model is conservatively at best proportionate to Italy’s share of total global population. Italy’s 2021 population was about 60 million people relative to a global population of 8 billion people (0.75% of earth’s total population). What’s the probability that when someone runs a query at OpenAI or Dall-e, it uses an Italian national’s data without their consent? While some might argue, data rights would be marginally violated on every query, I believe it’s more correct to say conservatively in a maximum of 0.75% queries. Weighing the probability of harm especially vs. the benefits outlined in the geopolitical section, makes it clear why the ban should be repealed:

Timing Mismatch – if you believe that OpenAI is causing harm to individual rights by leveraging personal data, you must also believe that a substantial amount of that harm has already been levied. GPT-4 is trained on 500 trillion parameters. Approximately 5 billion people are on the internet as active users, so if you illustratively assume even internet contribution, each person has been incorporated into the model ~100,000 times at a minimum. While GPT-5 will likely be trained on factors substantially higher than 500 trillion, a violation of individual rights 100,000 times already represents meaningful harm to data rights. When an individual searches a query on GPT-4 or Dall-e, they are increasing the number of times their rights were violated to 100,001, which is not meaningfully worse than the data that’s already been incorporated into the model. My broader point is that data rights advocates need to acknowledge that much of the harm of an LLM that’s already been trained on 500 trillion parameters has already been done with regards to harvesting data without consent. It is illogical to have allowed that harm to happen over the past decade while the model is being trained and then once the harm is done, not allow citizens to simultaneously reap the benefits of the model for which they sacrificed data. This illogical and is akin to letting your house get robbed and then refusing an insurance payout to get the value of your goods back:

Public Value Capture – many consumer internet companies take users’ data and monetize it in some way whether it be by selling it to advertisers or incorporating the data to create a better product to drive greater user adoption. Many times, this monetization is of little benefit to the actual consumer, especially in cases of advertising where their data is quite literally being segmented, sold and monetized to marketers. For example, Facebook operates in Italy and while Europe has cracked down on Facebook for GDPR violations, I see no reason why OpenAI should be treated worse than Facebook and totally banned from the region. This is especially because the way that the public data is utilized for OpenAI actually creates a public good rather than a private good. Facebook monetizes data in a private way by extracting profits behind-the-scenes from advertisers, whereas OpenAI turns its data into a publicly accessible open source model (public good). Facebook further limits who can access its data APIs in ways that many believe are anti-competitive (private good) where OpenAI turned GPT-4 totally open source. In cases where the level of value capture is public (open source software), nations should be more inclined to allow the proliferation of the software even if data rights are at stake. I propose a framework of comparing probability of harm (how often your data is used) and level of value capture (public vs. private) for governments evaluating these sorts of decisions to ban technology products:
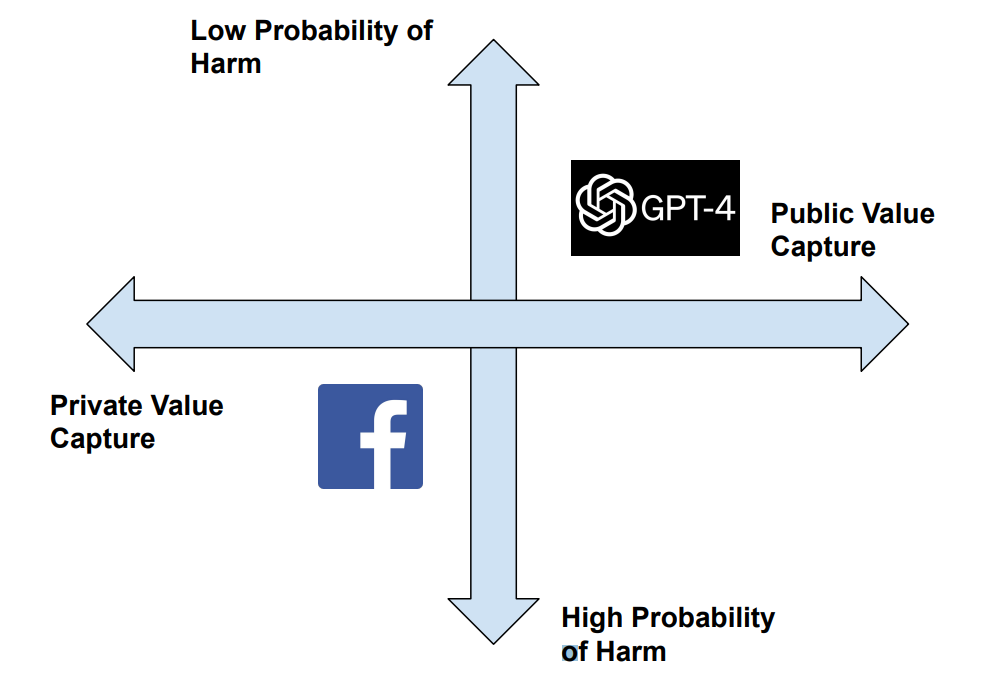
Given queries use only trace amounts of individual data attributable to each output, GPT-4 offers a service with low probability of harm through an open source product that aggregates value at the public level.
All Innovation Armory publications and the views and opinions expressed at, or through, this site belong solely to the blog owner and his guests and do not represent those of people, employers, institutions or organizations that the owner may or may not be associated with in a professional or personal capacity. All liability with respect to the actions taken or not taken based on the contents of this site are hereby expressly disclaimed. These publications are the blog owners’ personal opinions and are not meant to be relied upon as a basis for investment decisions.